Making it Look Amazing
Architectural visualization firm Studio 4D delivers real-time VR with BOXX Cloud.
Read More
Architectural visualization firm Studio 4D delivers real-time VR with BOXX Cloud.
Read More
BOXX Cloud delivers the trifecta for a Texas civil engineering, surveying, and landscape architecture firm.
Read More
U.S. Chamber of Commerce video producer and event technology lead Micky Ronis relies on BOXX Cloud to deliver custom, TV-quality webcast experiences.
Read More
Challenged by rapid growth and a full transition to Autodesk Revit, leading architecture firm KTGY found their solution in FLEXX data center platforms and BOXX Cloud.
Read More
The first film school inside a major studio development, S.I.C. Film School provides access to VR, AR, XR and BOXX.
Read More
Million Dollar Snare Mastering Engineer Nicolas de Porcel disrupts the recording industry with BOXX.
Read MoreU.S. Chamber of Commerce video producer and event technology lead Micky Ronis relies on BOXX Cloud to deliver custom, TV-quality webcast experiences.
Read More
The fun (and not-so-fun) challenges of Eric Keller, the CG artist who straddles a creative line between entertainment (Aquaman and John Wick 3) and the bold future of scientific visualization.
Read More
The virtual production arm of Fox Feature Film Entertainment relies on world class artists, engineers. . . and some incredible hardware from BOXX.
Read More
Located in Rancho Cordova, CA and Minneapolis, MN, Elara Systems strategic and creative services provide stunning 3D animations, illustrations, and virtual reality for industrial, medical, and other organizations.
Read More
As our friends and neighbors in the tech mecca of Austin, Texas, the brilliant minds at Thrillbox provide an immersive media platform, spellbinding 360 content from all over the globe, and the only behavioral analytics platform designed for VR, AR, and 360 videos. How do they keep it thrill? With BOXX, of course.
Read More
Thanks to department chair Marty Fitzgerald, East Tennessee State University’s animation program runs on BOXX and educates 300 undergrads in four key areas of concentration: animation, VFX, visualization, and game development.
Read More
From "Apollo 13" and "Cast Away" to "Doonby" and "Tower", Gary Walker is the independent VFX supervisor who cares more about human stories (and human beings) than CGI science fiction blockbusters.
Read More
Steve Choo’s boutique design, VFX, and animation studio, My Active Driveway, goes big with BOXX, creating national commercials for high profile clients.
Download PDF
Meet Webster Colcord, the animator and motion capture artist who relied on a battle-scarred BOXX workstation to bring Seth MacFarlane's Ted to life. Learn more about Colcord's work 'flows', philosophies, and experiences in this exclusive BOXX interview.
Download PDF
When BOXX introduced the APEXX 5, the most advanced workstation in the world, Windsong Productions, a state-of-the art California production studio, was first in line, taking their creative business to new heights.
Download PDF
Over forty years after the premiere of Stanley Kubrick’s “2001: A Space Odyssey,” VFX designer/director Oliver Zeller and his partners at the NAU design collective pay homage to the legendary motion picture with a visually stunning short entitled “Immersive Cocoon.” Learn how a BOXX solution with 3ds Max helped make it all possible.
Download PDF
While creating VFX for a BBC television series, veteran CG artist Chris Taylor was part of a team assigned to produce 1800 VFX shots in only 6 months. The solution was BOXX. Now, as he completes his own feature film LVJ, he needs this sci fi indie to look like a Hollywood blockbuster. The answer again was BOXX.
Download PDF
Brian Stark (along with Judy Hahn) is the founder of Metro DMA and The Stark Agency. Their latest client, best-selling author Stephen King, contracted with them in 2007 to orchestrate a complete overhaul of the author’s websites stephenking.com and The Dark Tower Official Web Site.
Download PDF
Whether he’s creating iconic fantasy vehicles for Hollywood blockbusters like 'Tron: Legacy', 'Captain America', and 'Prometheus', or authoring books like Cosmic Motors™ and The Timeless Racer®, concept designer, producer, and author Daniel Simon runs on all cylinders with BOXX.
Download PDF
Talented illustrator Michael J. Brown, founder of Detroit-based Renderhaus, discusses why, after many years, he’s once again powering his premium architectural visualizations with BOXX.
Read More
Studio director and CTO Gabriel Benroth explains the design process and how BOXX FLEXX makes award-winning INC Architecture & Design a more flexible, successful firm.
Read More
When Olivia Smith needed a purpose-built laptop to run Autodesk Revit and Unreal Engine Twinmotion, she did what any sensible college student does—she called her dad. But not for the reason you think.
Read More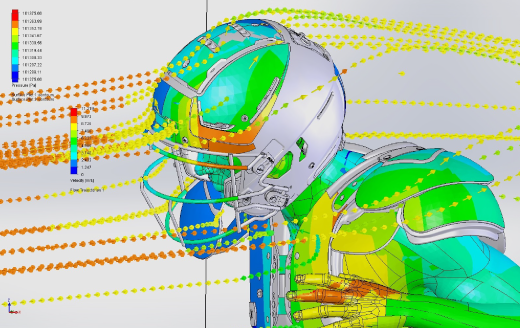
For the innovative Jay White of White Engineering, it’s all about the drag (and more). When conversing with Jay White of White Engineering, the listener is immediately captivated by what he has to say, not only because the subject matter is fascinating, but also because White has a genuine knack for talking about it.
Read More
Green Architect, Photographer, and Rock & Roll Sound Engineer Tapani Talo Stands Tall
Read More
With roughly $750 million in construction projects under his belt, Duane Addy has built a career on quality design and rendering production. As many organizations look to send project renderings to the cloud, Duane Addy has stood firm and put his trust in BOXX— a decision he can back with benchmarks.
Read More
Read how Enfinity Engineering’s Richard Howard became a BOXX champion.
Download PDF.jpg)
HMC Architects CAD manager and blogger Steve Bennett learned that you can “throw graphs and percentages and everyone else is doing it" until you are blue in the face, but what really gets them is “cold, hard cash.”
Download PDF
Award-winning Studio Rendering CEO Sonny Sultani discusses his company’s role in last year’s most expensive retail construction project and how BOXX workstations and renderPRO helped make it possible.
Download PDF
Piranha, known for creating innovative visuals for motion pictures, broadcast campaigns, network television, internet, and architecture visualization, relied on renderBOXX for their brilliant film, “The New World Trade Center.”
Download PDF
Leading “green” architecture firm, SERA Architects, is dedicated to the principles of urban revitalization, historic preservation, creative retro-fitting of existing buildings and sustainable design.
Download PDF
From bridges, ports, and dams, to sea battle sites and more, Abbott Underwater Acoustics’ Brian Abbott relies on sonar and BOXX to capture incredible images above and below the surface.
Read More
When the search was on for a ventilator device that could serve more COVID-19 patients, Robert Conley stepped up.
Read More
GOBOXX MXL VR is instrumental in the Canada-France-Hawaii Telescope Renovation. On the big island of Hawaii, atop the13,793 foot dormant volcano of Mauna Kea, sits the Canada-France-Hawaii Telescope (CFHT), a 3.6 meter optical/infrared telescope.
Read More
The Balance Between Speed and Quality The brilliant minds at Bluewrist deliver... with a little help from BOXX
Read More

BOXX solutions saved Accelerated Machine Design & Engineering $20-$50,000 a year, enabling the firm to put items “in space, in the ground, and in humans.”
Read More
Sponsored by BOXX, The University of Wisconsin BadgerLoop pod is competing in Elon Musk’s SpaceX Hyperloop competition . . . and attempting to change the world of transportation.
Read More
In a candid interview, Orange County Choppers senior designer Jason Pohl and media & marketing advisor Jim Kerr cut up and cut loose on the business, their workflows, and why the world’s most famous custom motorcycle shop is thrilled to be back with BOXX.
Read More
Dassault Systèmes case study reveals how BOXX utilizes SolidWorks to design the world's most advanced computer workstations.
Download PDF
Renowned designer Bill Gould relies on a BOXX workstation to stay ahead of his competition. When he got really serious about SolidWorks and KeyShot rendering, Bill opted for a workstation that was "bulletproof" while staying within his budget.
Download PDF
When presenting VRED automotive design software, Autodesk’s James Cronin relies on renderPRO. With up to 24 cores per node, renderPRO enables him to take a small renderfarm on the road for realtime design reviews and visualization.
Download PDF
SolidWorks expert and self-professed motorcycle and car enthusiast Matt Perez decided to create an advanced surfacing tutorial of a 2010 Chevy Camaro and make it available for free online.
Download PDF
How did a small design firm like MotoCzysz become the winningest American motorcycle manufacturer at the Isle of Man TT? Discover how BOXX keeps MotoCzysz in the lead.
Download PDF




